
[](https://www.nhncloud.com/kr)
## 들어가며
최근 MySQL 기반 서비스들로부터 ClickHouse 도입 문의를 받으면서 직접 검토하고 도입하게 되었습니다.
실제 운영 중인 서비스에 적용하며 성능을 확인할 수 있었고, 기술과 경험을 공유하고자 글을 작성했습니다.
## ClickHouse란?
[ClickHouse](https://clickhouse.com/)는 데이터를 빠르게 읽기 위해 만들어진 데이터베이스입니다.
MySQL은 행(Row) 단위로 데이터를 저장하고, ClickHouse는 열(Column) 단위로 데이터를 저장합니다.
행 단위 DBMS는 데이터를 블록 단위로 저장하고 읽기 때문에 일부 열만 필요한 쿼리라도 해당 행 전체 블록을 메모리에 올려야 합니다. 즉, 불필요한 열 데이터까지 I/O가 발생합니다.
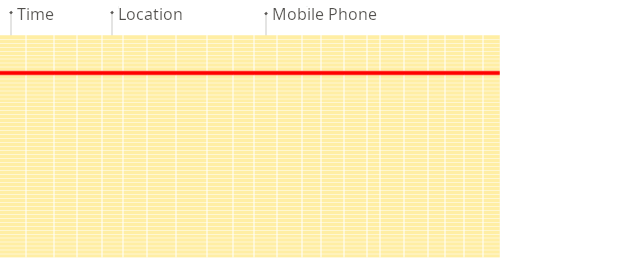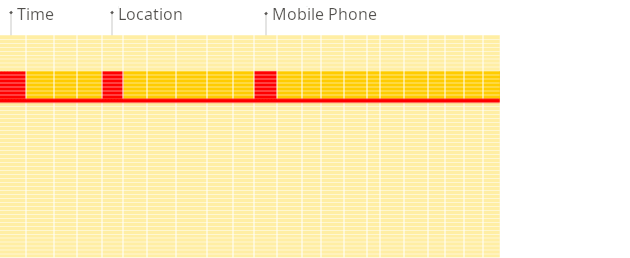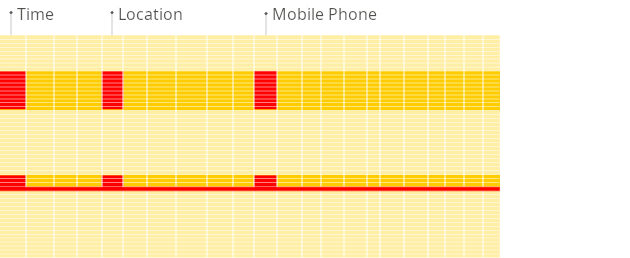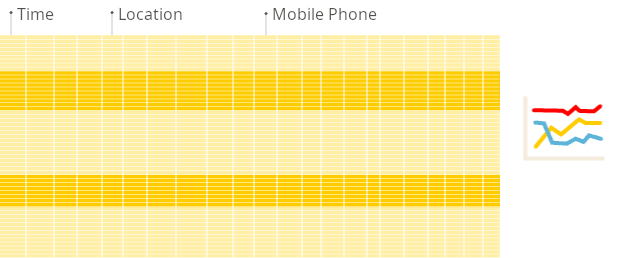
(source: [https://clickhouse.com/docs/intro](https://clickhouse.com/docs/intro))
반면 열 단위 DBMS는 열 단위로 데이터를 순차 저장하기 때문에 쿼리에 필요한 열만 선택적으로 읽을 수 있어 불필요한 I/O를 방지하고 분석 쿼리 성능이 크게 향상됩니다.
(source: [https://clickhouse.com/docs/intro](https://clickhouse.com/docs/intro))

따라서 SUM, COUNT, AVG 같은 집계 쿼리를 실행할 때 MySQL은 모든 열을 읽어야 하지만 ClickHouse는 필요한 열만 읽기 때문에 대량 데이터 조회에서 빠른 성능을 냅니다.
## MySQL의 한계, 그리고 ClickHouse
MySQL은 트랜잭션, 단건 조회/수정/삭제 작업에 현재도 널리 사용됩니다. 다만, 한계가 있습니다.
### MySQL이 한계를 보이는 순간
데이터가 수천만 건을 넘어가면서 집계 쿼리 하나가 30초, 1분, 그리고 타임아웃으로 이어지기도 합니다. 인덱스를 아무리 잘 잡아도, 읽어야 할 데이터 자체가 너무 많으면 성능 개선이 어렵습니다. MySQL은 행(Row) 단위로 저장하기 때문에 `SUM(amount)` 하나를 구하려 해도 모든 칼럼을 통째로 읽어야 해서 느립니다. 데이터가 쌓일수록 이 문제는 피할 수 없습니다.
### ClickHouse가 돌파한 지점
| MySQL의 한계 | ClickHouse의 해결 |
| --- | --- |
| 집계 쿼리 = 전체 행 풀스캔 | 필요한 칼럼만 읽는 열 저장 구조 |
| 인덱스로 한계, 수억 건은 답 없음 | 파티션 + 정렬 키로 읽는 범위 자체를 줄임 |
| 무거운 쿼리 1개가 전체 DB 영향 | 병렬 처리로 쿼리 간 간섭 없음 |
| 대용량 적재 시 성능 저하 | 배치 INSERT에 최적화된 구조 |
| 저장 공간 그대로 |